Scoring Concepts
Qualified is centered around the idea of assessing software developers using "work samples," a testing style that offers tasks related to the role being assessed for. Coding challenges are the primary challenge type used for assessing these work tasks. Q&A challenges are often used to expand on the work sample, or to supplement it by testing additional knowledge.
Since developers are being tested on their ability to complete certain types of tasks, scoring in Qualified takes a criterion-referenced approach.
Criterion-Referenced Validity
Criterion-referenced means that the candidate is being assessed on their ability to achieve a standard. A standard is the level of competency necessary to perform well within a job role. In the case of most challenges on the Qualified platform, the candidate is expected to be able to at least complete the task. This is why most challenges expect a candidate to achieve a 100% accuracy score.
This is an important concept to remember, because Qualified is primarily concerned with ensuring candidates meet a certain standard, not comparing performance of candidates to one another (that is, a norm-referenced scoring approach). This is not to say that candidates can't prove themselves to be more capable than others. This is where quantitative versus qualitative scoring comes in, and that leads us to autonomous versus human-based scoring.
Accuracy Score
Each challenge type on Qualified platform has a method for being automatically scored. Scores are calculated as the candidate progresses through the challenge and on final submission. A single percentage score is shown next to each assessment result. This score represents the accuracy score for the assessment. This score represents candidate's combined average percentage solved of all challenges within the assessment.
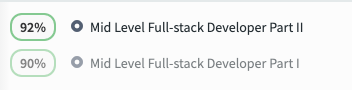
For example, if there are 3 challenges in an assessment and a candidate submits scores of 100%, 50% and 100% on the challenges, the assessment "accuracy" score will be (100 + 50 + 100) / 300 = 83%. Every challenge on the assessment is weighted the same when it comes to determining the assessment "accuracy" score.
Challenges are scored differently depending on whether the challenge is a coding challenge or a set of questions and answers.
Coding Challenges
The two formats Qualified offers for delivering a coding challenge, Classic Code Challenges and Project Code Challenges, are scored using submission unit tests. Each unit test is weighted equally in computing the overall accuracy score. If there are 10 unit tests and the candidate passes 8 of them, the candidate's score will be 80%. In other words, by default, the score for Code Challenges are a reflection of number of unit tests passed. The score is never more than 100%.
Q&A Challenges
Question & Answer Challenges contain individual questions that each contribute one point by default. Total points are divided by earned points to calculate the "accuracy" score. For example, if there are two questions — one worth 2 points and the other worth 1 — then the questions will count for 67% and 33% of the total score respectively.
Each question can also allow partial scores, which means that only a portion of the total points are earned based on the candidate's answers. For example, there could be a multiple choice question that asks for 4 choices to be selected out of 10. Each correct choice is assigned one point. If the candidate answers 2 of the choices correctly, then they will only earn 2 points instead of 4.
You can assign choices different weights. In this way, particular responses to a question can be worth more or less than others in determining the total score for the question.
You can review these options in more detail within our Q&A question reference documentation.
Ratings
Quantitative and some qualitative scoring can be handled autonomously. However, a typical hiring team will manually inspect work samples in order to distinguish among top automatically-scored candidates. Qualified offers guided scoring and reviews as a framework for teams to review work samples. One or more members of the team can review each assessment result and provide subjective and objective ratings of candidate performance.
Subjective Ratings
Subjective ratings don't require a rubric and are simply a team member's opinion of the candidate's performance. Typically, subjective ratings are used to signal to a hiring manager whether the candidate should move forward in the hiring process or not.
Qualified provides an overall rating and a set of individual qualities that can be rated per challenge. This allows each reviewer to provide subjective feedback and insights. Additionally, an overall approval or rejection can be applied to an assessment result.
Reviews do not count as part of the accuracy score. Instead, you will see a green, yellow or red dot next to the score within the candidates list which represents each reviewer's overall rating.
Objective Ratings
While subjective ratings allow for free-form feedback and are great for communicating overall opinions, they do not provide a consistent process for measuring qualitative aspects of candidate submissions. If you are looking to have your reviewers provide clear feedback on candidate performance within pre-established categories, you can define a set of score cards that guides reviewers to provide consistent and objective feedback. Each score card rating can have its own rubric defined for it to help reviewers standardize their feedback.
When dealing with score cards, we start to get into deeper aspects of qualitative assessment measurement. This is where our advanced scoring features comes in.
Advanced Scoring
Limited Beta
This section describes a new set of features currently in beta. If you are interested in learning more, please reach out to our sales team.
Qualified Score
So far we have discussed the two entry-level scoring features of the platform, accuracy scores and subjective ratings. These are fundamental to everyone using the platform. In addition to these, the Qualified Score is a new scoring feature that provides an overall score for a candidate.
The Qualified Score is determined through a new scoring system which we call "Evidence Engine". This engine allows a high degree of configuration to collect different data signals and weight and map them into a single Qualified Score. This score acts as a single value that you can use to quickly identity how strong a candidate is.
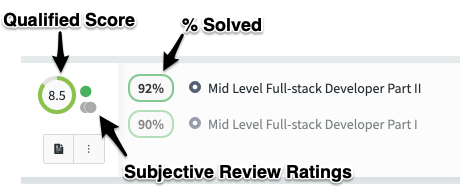
The Qualified Score is a value between 0 - 10 and incorporates all evidence signals collected by the system. Signals can includes things such as the accuracy score, as well as other signals, such as reviewer score card ratings provided by your team after conducting an assessment review. Additional system scored signals are also in the works.
Qualified Score Confidence
When reviewing a candidate's report card, you will notice a "Qualified Score Confidence" value. This value is from 0 - 100% and it is useful for determining how many signals have been scored, compared to how many signals could be scored given the current candidate activity. We don't get to deep into this now, but keep in mind that this value is really about understanding if there is more your team can do to fill in gaps about the candidate. Typically, the confidence will be low if the candidate has not been reviewed yet, or has an incomplete review.
Any signals which have not been scored yet will be completely removed from the Qualified Score (and related subscores). This means a candidate score could go down once your team reviews the quality of their submissions.
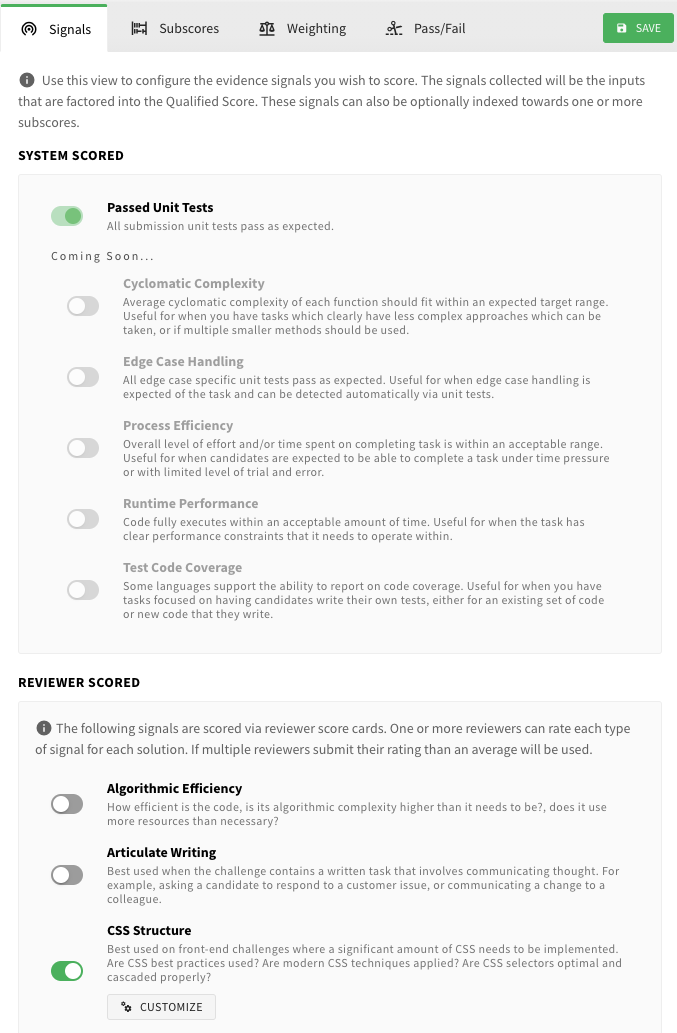
Evidence Engine
The Evidence Engine is a powerful platform feature that allows various data (signals) to be defined, structured and eventually translated into scores. This engine is what powers our advanced report cards, as well as the Qualified Score.
When a candidate takes an assessment, they produce a set of evidence data that can be used to signal various things. This evidence includes performance data, such as how fast they completed the assessment and how many unit tests they passed. The challenges contained in each assessment are typically designed to be scored across multiple areas. Correctness/completely is the most common, but they can also include qualitative aspects which your team can review and rate.
As your team reviews each submission and rates the quality of candidate's solutions, more evidence is collected. This evidence is turned into input signals, which are fed into the Evidence Engine and mapped and weighted to determine how the Qualified Score will be affected. Additional subscores can also be determined, each with their own combination of signals that comprise their score. As a candidate takes multiple challenges, potentially across multiple assessments, all of these scores get aggregated and weight averaged into an overall Qualified Score, and overall subscores which are shown on the candidate's report card.
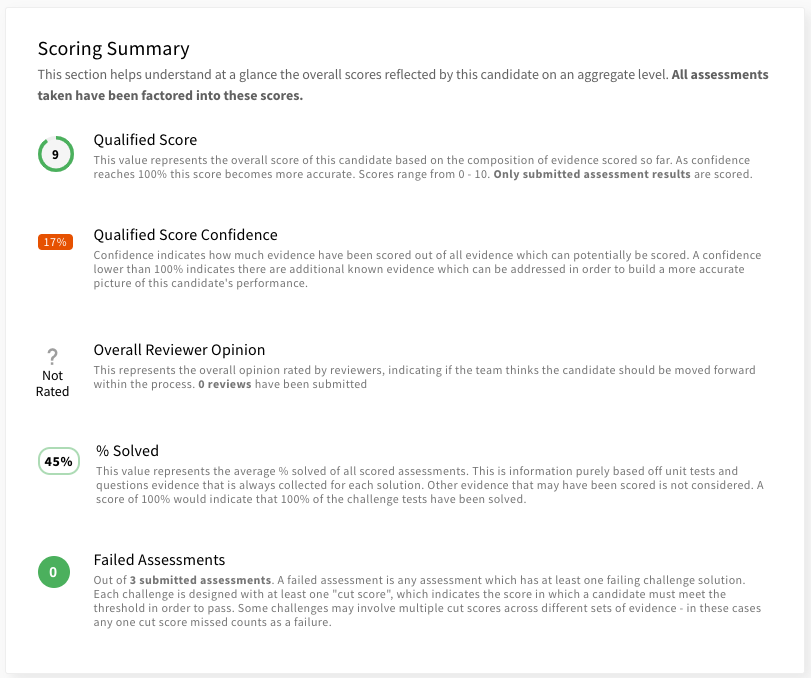
Report Cards
Report cards are how the data from the Evidence Engine gets presented. They include comprehensive data on all evidence collected, and all scores aggregated. They also incorporate evidence signals that may not have yet been collected, such as reviewer scored cards. By viewing reports cards and seeing signals that have not yet been scored, its easy to determine if the candidate has done well enough so far that you want your team to take a deeper look. All of this allows you to create a structured and consistent evidence-based process.
We have only touched briefly on the evidence engine. Since this is an advanced topic, we will not get into too much depth on it now. If you do wish to dive in, you can jump to our in-depth article.
Otherwise, now that we have covered the conceptual basics of the system, let's work on getting your account fully set up.